
日レセの氏名欄の漢字表記問題「■の文字」
WindowsのOfficeなどで漢字を入力表示出来ても、入力したデータを日レセの患者登録画面の漢字氏名入力欄でエンターして再表示させると「髙」の漢字のように■
「髙」の漢字のような場合は、JISX0208:1983(第1、第2水準)の文字「6,879文字」JISX0213:2004(JIS第3水準,第4水準)までの文字「11,233文字」以外の文字の場合となります。
オンライン請求の送信データで使われる漢字&日レセでの漢字
JISX0208:1983(第1、第2水準)の文字「6,879文字」以外の漢字データはオンライン請求では送る事が出来ず、それ以外の文字が使われた場合は、日レセでは送信データの氏名漢字にはカナ氏名が自動的にセットされるようになっています。
オンプレ版ORCAで文字タイプがEUC-JPの場合の漢字入力は、このJISX0208:1983(第1、第2水準)の文字「6,879文字」しか扱えないようになっています。
クラウド版ORCAは拡張漢字に対応
クラウド版ORCAの場合は文字タイプがutf-8の場合プログラム内部の定義でJISX0213:2004(JIS第3水準,第4水準)までの文字「11,233文字」まで扱えるようになっています。これはJISX0208:1983(第1、第2水準)の文字「6,879文字」を含みます。この漢字を拡張漢字と言います。
「﨑」の漢字などがそうです。JISX0213:2004(JIS第3水準,第4水準)までの文字「11,233文字」には含まれているがJISX0208:1983(第1、第2水準)の文字「6,879文字」には含まれていない。ただ、こうした漢字は支払基金や国保連に送信するデータでは使えない漢字ですので、レセ電処理ではカタカナに自動的に置き換えられてレセ電等は作成されるようになっています。
また日レセでJISX0213:2004 (JIS第3水準,第4水準)が使用出来るのは「氏名漢字」欄のみとなっています。
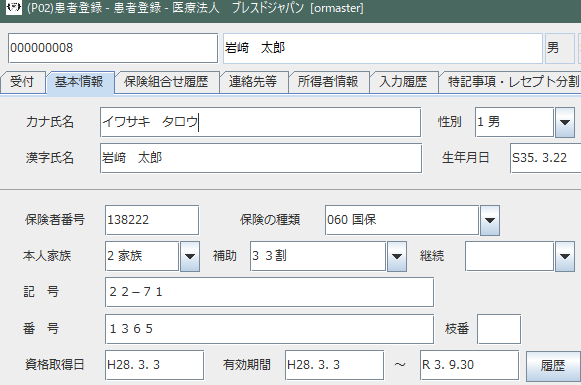
拡張漢字の入力は普通に出来ます。

レセプトも普通に印刷出来ます。
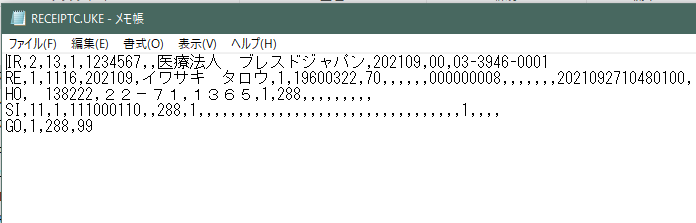
しかし、国保への送信データを作成すると名前はカタカナが使われています。
従って、このデータが国保連から紙返戻で郵送されて来た場合には名前が上記のように漢字表記されなくてカタカナ表記されたレセプトが送られて来るはずです。
- 投稿タグ
- 日医標準レセプトソフト






